
Lester Phillip Violeta
Ph.D. Candidate
Nagoya University, Japan
I am a final year (!) Ph.D. student at Nagoya University, Japan at Toda Laboratory under the supervision of Professor Tomoki Toda through a full scholarship from the Monbukagakusho Japanese Government. My research mainly focuses on speech synthesis, particularly with electrolaryngeal speech data and singing voice data.
My work has been published in top speech and audio conferences/journals such as Interspeech, ICASSP, ASRU, SLT, and TASLP. I have also been involved in several academic activities, where I was co-organizer of the recent Singing Voice Conversion Challenge in 2023 (and also co-organizing 2025!). I am also part of the peer-review committee for several academic conferences such as ASRU, SLT, ICASSP, Interspeech, IJCNN, and journals like IEEE JSTSP.
Aside from research, I also have various experiences in the engineering side, creating custom models and deploying these as products for companies. I am currently a part-time speech researcher at CoeFont in the voice conversion team. Previously, I was also a founding AI engineer at VoiceSwap.AI and have also worked on research internships at Sony Computer Science Laboratories Tokyo, NTT Media Intelligence Laboratories, and Hitachi Ltd. Thus, I have extensive experience in both the academic research and engineering sides of AI.
I have a deep international background now studying in Japan, and having done my B.S. in the Philippines and done a research exchange in France. Outside of programming, I like bouldering (check out this page) and learning Japanese.
Education
Nagoya University, Japan
Ph.D. in Computer Science
Advisor: Prof. Tomoki Toda
Thesis: Speech Recognition, Voice Conversion
Ateneo de Manila University, Philippines
B.S. Electronics Engineering
Thesis: Renewable Energy, Microgrid Optimization
Institut Catholique d'Arts et Metiers Paris, France
Research Exchange Semester
Thesis: Renewable Energy, Microgrid Optimization
Publications
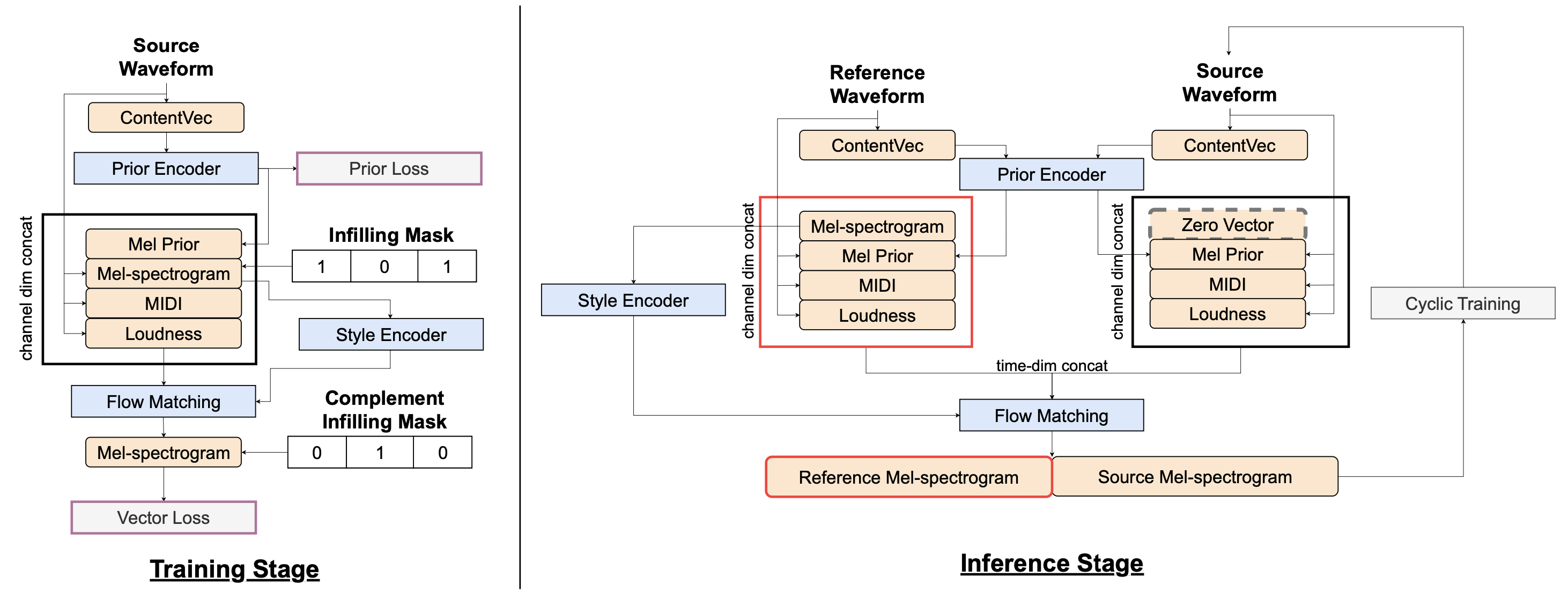
ICASSP 2024
Electrolaryngeal Speech Intelligibility Enhancement through Robust Linguistic Encoders
Lester Phillip Violeta, Wen-Chin Huang, Ding Ma, Ryuichi Yamamoto, Kazuhiro Kobayashi, Tomoki Toda
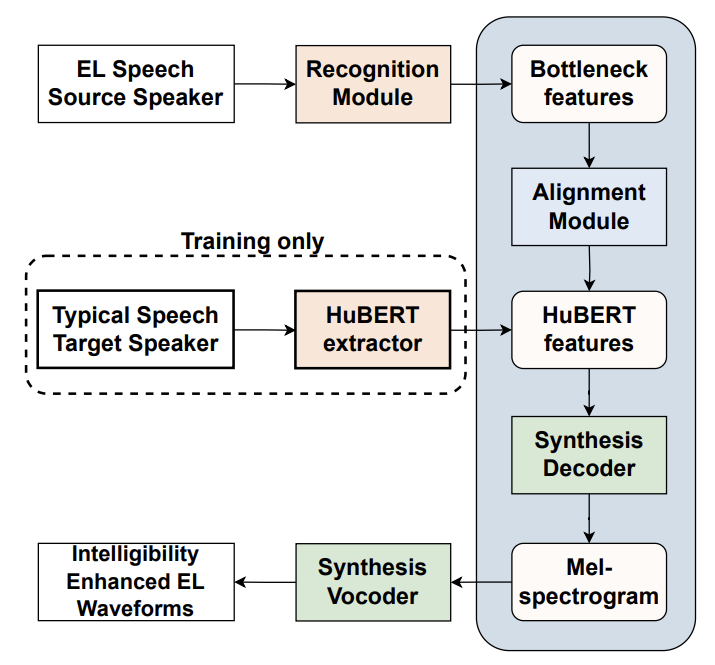
IEEE/ACM TASLP 2024
Pretraining and Adaptation Techniques for Electrolaryngeal Speech Recognition
Lester Phillip Violeta, Ding Ma, Wen-Chin Huang, Tomoki Toda
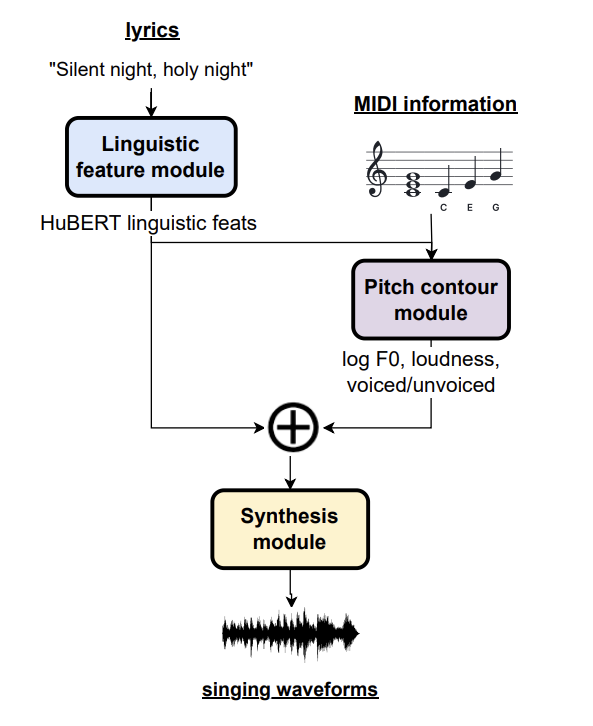
Technical Report 2024
A Preliminary Investigation on Flexible Singing Voice Synthesis Through Decomposed Framework with Inferrable Features
Lester Phillip Violeta, Taketo Akama
ASRU 2023
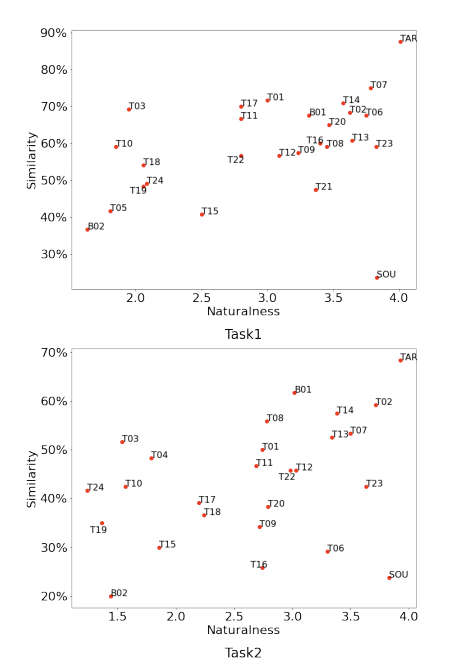
The Singing Voice Conversion Challenge 2023
Wen-Chin Huang, Lester Phillip Violeta, Songxiang Liu, Jiatong Shi, Tomoki Toda
APSIPA 2023
An Analysis of Personalized Speech Recognition System Development for the Deaf and Hard-of-hearing
Lester Phillip Violeta, Tomoki Toda

ICASSP 2023
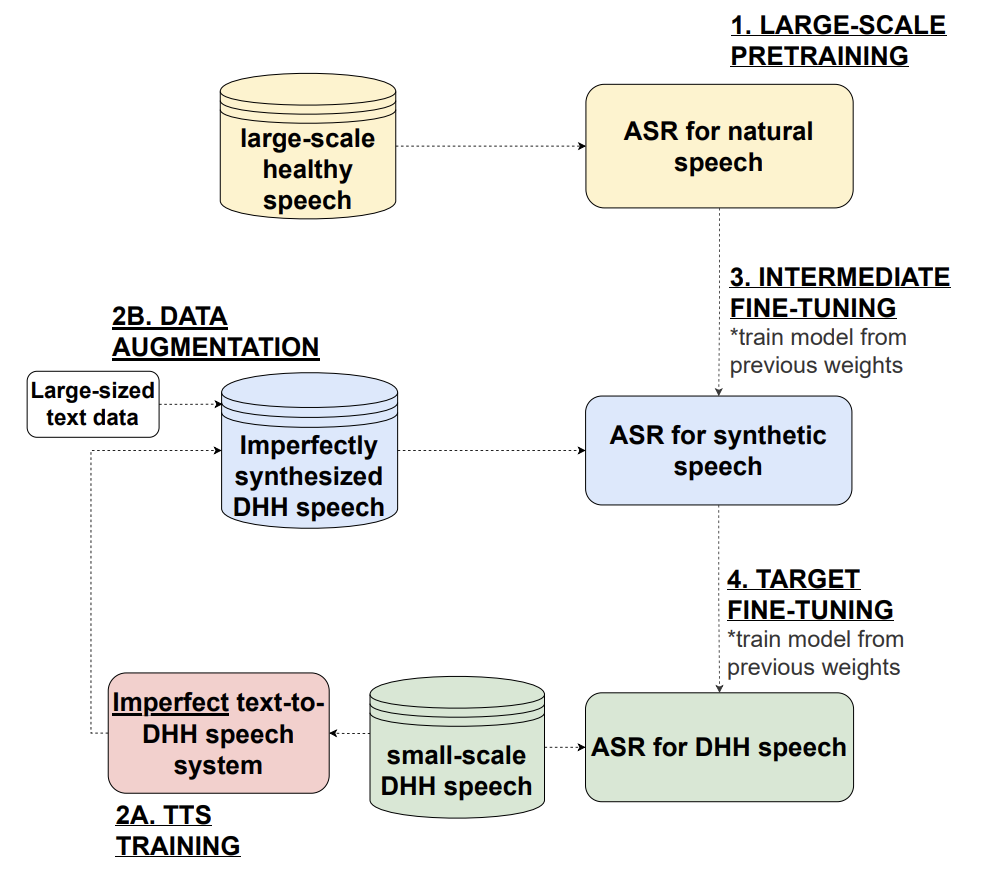
Intermediate Fine-tuning Using Imperfect Synthetic Speech for Improving Electrolaryngeal Speech Recognition
Lester Phillip Violeta, Ding Ma, Wen-Chin Huang, Tomoki Toda
Interspeech 2022
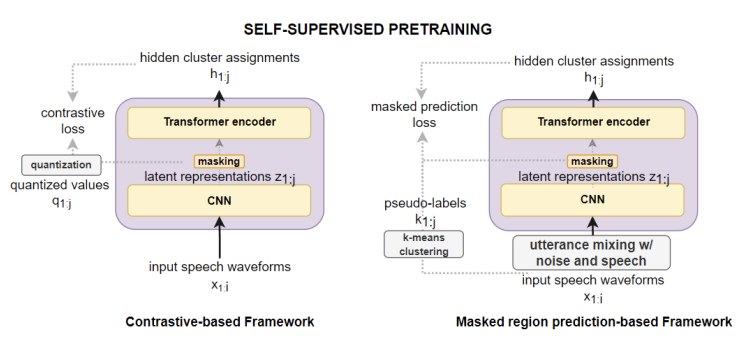
Investigating Self-Supervised Pretraining Frameworks for Pathological Speech Recognition
Lester Phillip Violeta, Wen-Chin Huang, Tomoki Toda
Experience
Researcher — CoeFont
Part-time, voice conversion team
Founding AI Engineer — Voice-Swap.AI
Custom singing voice conversion models and speech synthesis for B2B customers
Research Assistant — Sony CSL Tokyo
Manager: Dr. Taketo Akama
Research on singing voice synthesis systems
Research Intern — NTT Media Intelligence Laboratories
Manager: Dr. Atsushi Ando
Research on speech diarization systems
Research Intern — Hitachi Ltd.
Manager: Dr. Takashi Sumiyoshi
Research on low-resourced speech recognition